收费技术咨询微信:
OBSStudio
我们制作了一个用于实时变声的界面go-realtime-gui.bat/gui_v1.py(事实上早就存在了),本次更新重点也优化了实时变声的性能。对比0813版:
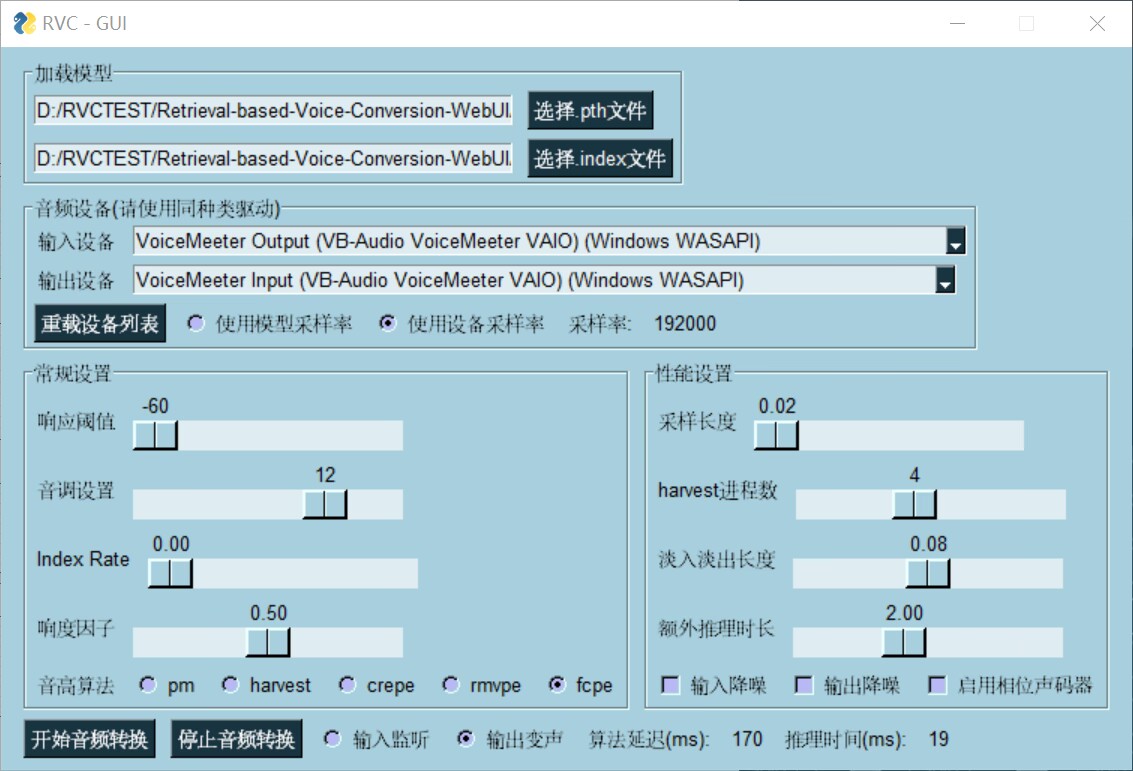
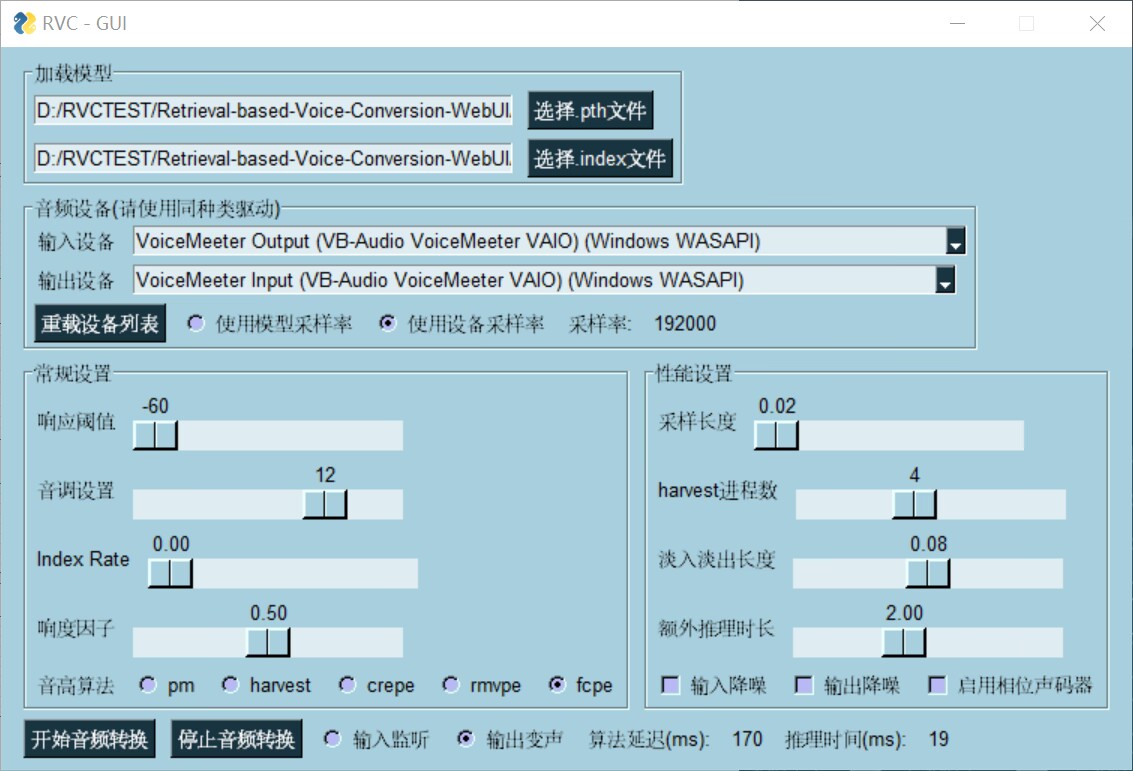
注意输入输出设备应该选择同种类型,例如都选MME类型。
1006版本整体的更新为:
底模使用接近50小时的开源高质量VCTK训练集训练,无版权方面的顾虑,请大家放心使用
请期待RVCv3的底模,参数更大,数据更大,效果更好,基本持平的推理速度,需要训练数据量更少。
| 训练推理界面 | 实时变声界面 |
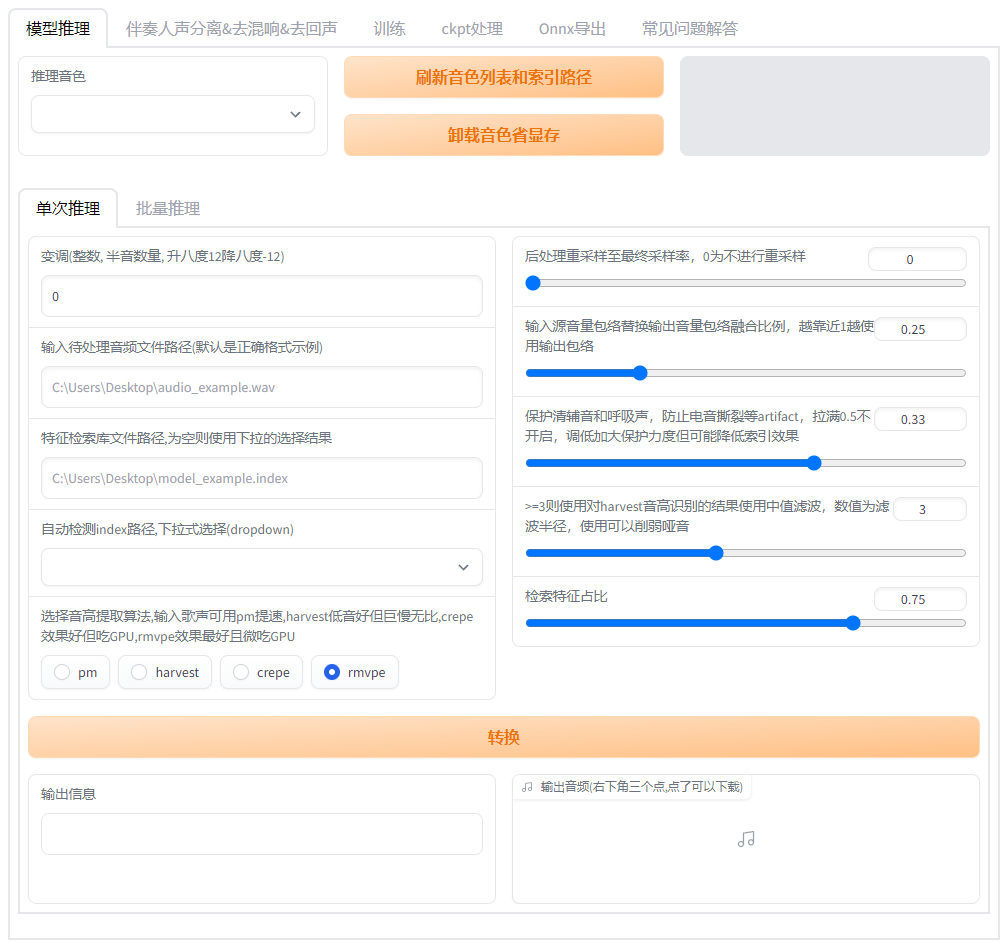 |  |
| go-web.bat | go-realtime-gui.bat |
| 可以自由选择想要执行的操作。 | 我们已经实现端到端170ms延迟。如使用ASIO输入输出设备,已能实现端到端90ms延迟,但非常依赖硬件驱动支持。 |
本软件具有以下特点
点此查看我们的演示视频 !
以下指令需在 Python 版本大于3.8的环境中执行。
下列方法任选其一。
pip install torch torchvision torchaudio
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
pip install -r requirements.txt
pip install -r requirements-dml.txt
pip install -r requirements-amd.txt
pip install -r requirements-ipex.txt
安装 Poetry 依赖管理工具,若已安装则跳过。参考自: https://python-poetry.org/docs/#installation
curl -sSL https://install.python-poetry.org | python3 -通过 Poetry 安装依赖时,python 建议使用 3.7-3.10 版本,其余版本在安装 llvmlite==0.39.0 时会出现冲突
poetry init -npoetry env use "path to your python.exe"poetry run pip install -r requirments.txt可以通过 run.sh 来安装依赖
sh ./run.sh
RVC需要其他一些预模型来推理和训练。
你可以从我们的Hugging Face space下载到这些模型。
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称。你可以在tools文件夹找到下载它们的脚本。
./assets/hubert/hubert_base.pt
./assets/pretrained
./assets/uvr5_weights
想使用v2版本模型的话,需要额外下载
若ffmpeg和ffprobe已安装则跳过。
sudo apt install ffmpeg
brew install ffmpeg
下载后放置在根目录。
下载ffmpeg.exe
下载ffprobe.exe
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录。
如果你想基于AMD的Rocm技术在Linux系统上运行RVC,请先在这里安装所需的驱动。
若你使用的是Arch Linux,可以使用pacman来安装所需驱动:
pacman -S rocm-hip-sdk rocm-opencl-sdk对于某些型号的显卡,你可能需要额外配置如下的环境变量(如:RX6700XT):
export ROCM_PATH=/opt/rocmexport HSA_OVERRIDE_GFX_VERSION=10.3.0同时确保你的当前用户处于render与video用户组内:
sudo usermod -aG render $USERNAMEsudo usermod -aG video $USERNAME使用以下指令来启动 WebUI
python infer-web.py
若先前使用 Poetry 安装依赖,则可以通过以下方式启动WebUI
poetry run python infer-web.py
下载并解压RVC-beta.7z
双击go-web.bat
sh ./run.sh
source /opt/intel/oneapi/setvars.sh